
6月12日,由之江实验室王聪博士领衔的科研团队联合新奥科技、浙江大学、澳大利亚新南威尔士大学的科研人员以及数据合作方——核工业西南物理研究院与中科院等离子体物理研究所,通过开发一种物理信息驱动的深度学习模型架构,为核聚变诊断代理模型研究提供了新路径。相关研究成果已发表在核聚变权威期刊《Nuclear Fusion》上,标题为《Physics-informed deep learning model for line-integral diagnostics across fusion devices》。

一、研究背景
在核聚变研究中,从线积分测量数据中快速重建二维等离子体剖面参数对于托卡马克装置的实时控制和决策至关重要——精确的内部等离子体状态信息可显著提升运行安全性和效率。当前的等离子体剖面重建方法主要分为两类:
一是基于物理模型的重构方法:精度高,但是依赖复杂的物理方程和仿真计算,通常需要巨大的计算成本;而且还需要考
虑空间时间动力学、多物理场耦合及系统相互作用,其复杂性不仅增加了计算时间,也限制了诊断反馈的频率和响应速度。
二是基于数据驱动的
代理模型:由于前一种方法存在弊端,代理模型方法应运而生。近年来,国内外多支科研团队已经在利用神经网络重构和预测等离子体特性方面取得显著进展,但仍存在局限性,如现有模型(主要依赖经典神经网络架构)未能充分整合诊断系统原理和物理信息(PI)等等。
二、研究目的
为解决上述方法存在的局限性,科研团队旨在通过本项研究开发一种物理信息驱动的深度学习模型架构,以提高从线积分诊断数据重建等离子体分布的性能,实现快速、准确且符合物理规律的重建,从而为核聚变研究提供更高效的数据分析工具,助力可持续核聚变能源的发展。
三、研究方法
1.实验数据集构建
科研人员收集了来自EAST和HL-2A两个托卡马克装置的软X射线诊断实验数据,构建了两个实验数据集:Exp_EAST和Exp_HL-2A分别包含43,378 和765,200个样本。其中:Exp_EAST数据集包含稳态放电与磁流体动力学(MHD)不稳定放电两类数据,而Exp_HL-2A数据集仅包含稳态放电数据。
2.合成数据集开发
科研团队还开发了一种合成数据模型,并基于该模型生成了包含目标剖面和线积分诊断虚拟诊断数据的合成数据集:Synthetic_EAST和Synthetic_HL-2A。合成数据严格遵循线积分原理,无算法误差。

3.模型架构设计
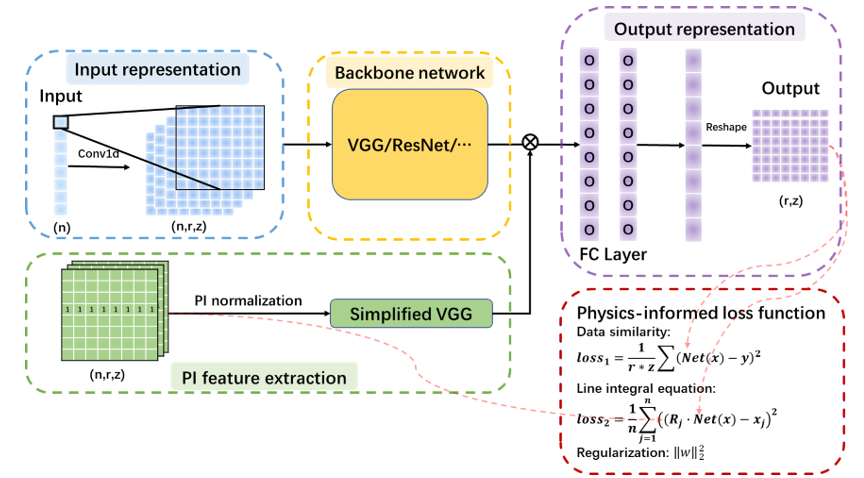
科研团队提出了名为Onion的物理信息驱动模型架构,其核心在于将物理信息(如线积分诊断系统的响应矩阵)整合到模型中。
该模型包括输入表示层(Input representation)、物理信息特征提取侧链(PI feature extraction)、骨干网络层(Backbone network)、输出表示层(Output representation)以及物理信息驱动的损失函数(Physics-informed Loss Function,PILF)。其中:
- 输入表示层:将诊断数据转换为更高维形式以便更好地提取特征并与物理信息融合;
- 物理信息特征提取侧链:通过简化版VGG-Net提取诊断物理信息;
- 骨干网络层:可灵活选择不同高性能神经网络结构;
- 输出表示层:由两个全连接层构成,用于最终输出计算;
- 物理信息驱动的损失函数:结合均方误差、基于线积分原理的物理约束损失和L2正则化项,以确保模型预测结果既与目标分布接近,又符合物理定律。
四、实验结果及结论
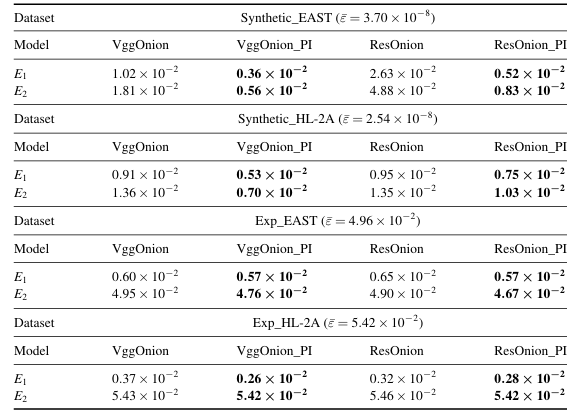
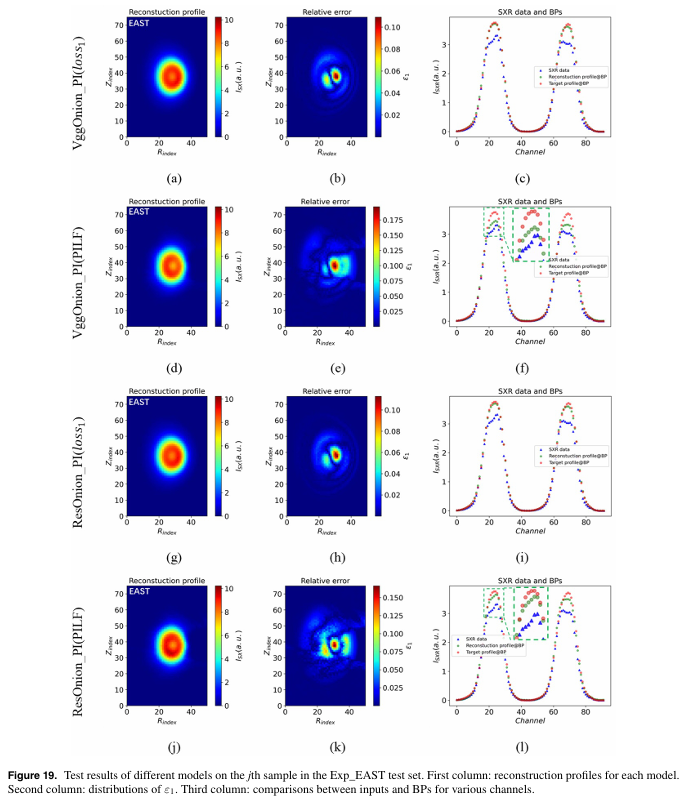
1.物理信息能有效提升模型性能
在合成数据集上,引入物理信息的模型(如VggOnion_PI和ResOnion_PI)相比未引入的模型,平均相对误差E₁降低了约0.84×10⁻²,E₂降低了约1.57×10⁻²;在实验数据集上,E₁平均降低约0.06×10⁻²,E₂基本不变。这表明物理信息的引入在合成数据集上对模型性能提升显著,但在实验数据集上因数据自身的固有误差,提升效果有限。
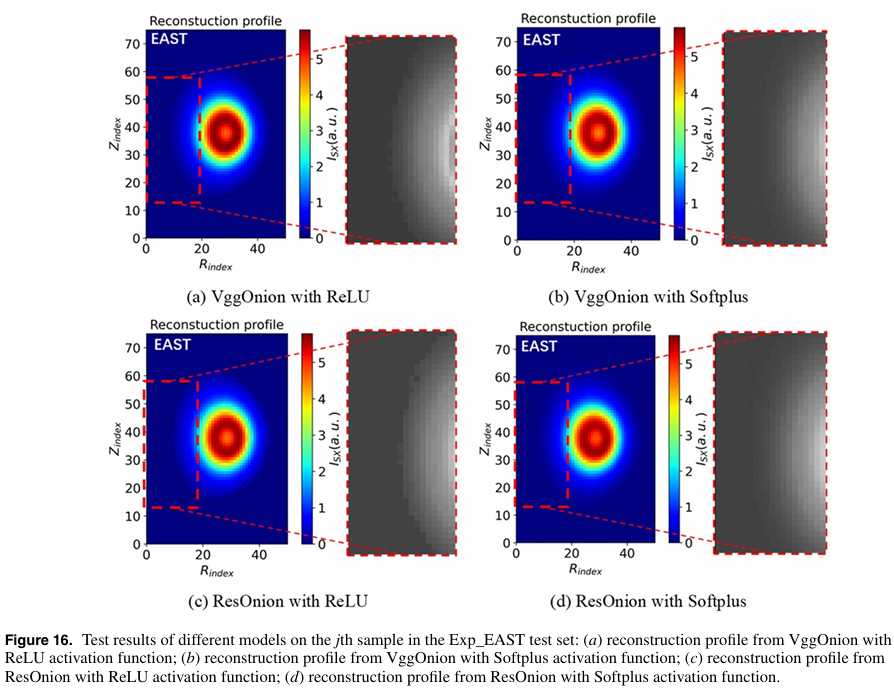
2.Softplus激活函数使得重建剖面更加平滑
使用Softplus激活函数替代ReLU激活函数后,在合成数据集上,模型的E₁平均降低约1.06×10⁻²,E₂平均降低约1.87×10⁻²;在实验数据集上,E₁平均降低约0.11×10⁻²,E₂平均降低约0.12×10⁻²。Softplus激活函数使重建剖面的边缘更平滑,更符合物理实际。
3.物理信息驱动损失函数(PILF)显著增强模型预测效果
在实验数据集Exp_EAST上,当超参数c₁设为0.618时,应用PILF的模型相比仅使用loss₁的模型,E₂平均降低0.95×10⁻²;而在实验数据集Exp_HL-2A,当c₁设为1.0时,E₂平均降低4.59×10⁻²,表明PILF有效增强了模型预测结果对实验约束的满足能力,且效果与超参数c₁的取值相关。
六、局限性
- 数据局限性:所使用的训练数据缺乏实验测量的不确定性信息,这限制了模型在不确定性相关研究和分析方面的应用能力,无法对结果进行更全面的不确定度量化和分析。
- 物理信息局限性:目前模型整合的物理信息和PILF仅涉及线积分相关响应矩阵信息,尚未涵盖MHD等更广泛的物理知识,导致在处理MHD不稳定放电场景时,模型的表现可能不够理想,对存在磁岛等复杂特征的数据重建效果不佳。
- 数据集误差影响:实验数据集自身的固有误差会对模型性能提升效果产生负面影响,可能使模型难以有效区分有用信息和噪声,限制了因引入物理信息等手段带来的性能优化幅度。
七、未来展望
- 模型拓展与优化:计划将模型应用于不同放电阶段和更广泛的实验场景,如限制器和偏滤器情景、尖峰和凹陷发射分布等,以进一步验证和完善模型。同时,探索整合更多种类的物理信息,如MHD相关知识以及其他诊断系统的信息,以增强模型对复杂等离子体现象的建模和预测能力。
- 数据质量提升:未来将努力获取包含不确定性信息的实验数据,以丰富数据集内容,使模型能够进行更深入的不确定性分析,提高结果的可靠性。此外,随着更先进的诊断技术和数据分析方法的发展,有望进一步提高数据质量,为模型训练和优化提供更有力的支持。
- 技术融合与创新:考虑采用混合专家架构和联邦学习策略,以充分发挥不同模型的优势,提高模型在处理不同实验放电场景时的性能和泛化能力,为核聚变研究提供更强大、更智能的工具和技术。
本研究通过Onion模型架构的提出与验证,建立了物理原理与深度学习融合的新范式,为核聚变线积分诊断提供了高效、准确的代理模型解决方案。尽管当前存在数据与物理信息整合的局限,但该方向通过技术迭代有望推动聚变诊断从 “事后分析” 向 “实时智能控制” 跨越,加速可控核聚变能源的工程实现进程。
主要作者简介:王聪,2022年博士毕业于中国科学技术大学,现就职于之江实验室。研究课题为基于AI的托卡马克诊断集成数据分析研究,从事聚变诊断系统的贝叶斯反演算法、诊断物理信息神经网络代理模型研究。